Hi everyone!
Wow, what a term. Nothing has gone quite as planned! It has been an extraordinarily tough term to try to learn some math.
This will be the last required problem set of the term. I will try to ask some problems which will help you understand the current material. I will also try to ask some problems which will show you some (I think) magical things, which may provide some “closure” to the class.
I started the term promising a solution to the Kepler problem. I won’t put that in this required problem set (since physics is not everyone’s thing), but I am hoping to put it in an “epilogue” lecture/problem set after this one, if I have the time and energy . . .
Anyway, let’s get started!
Exponentials
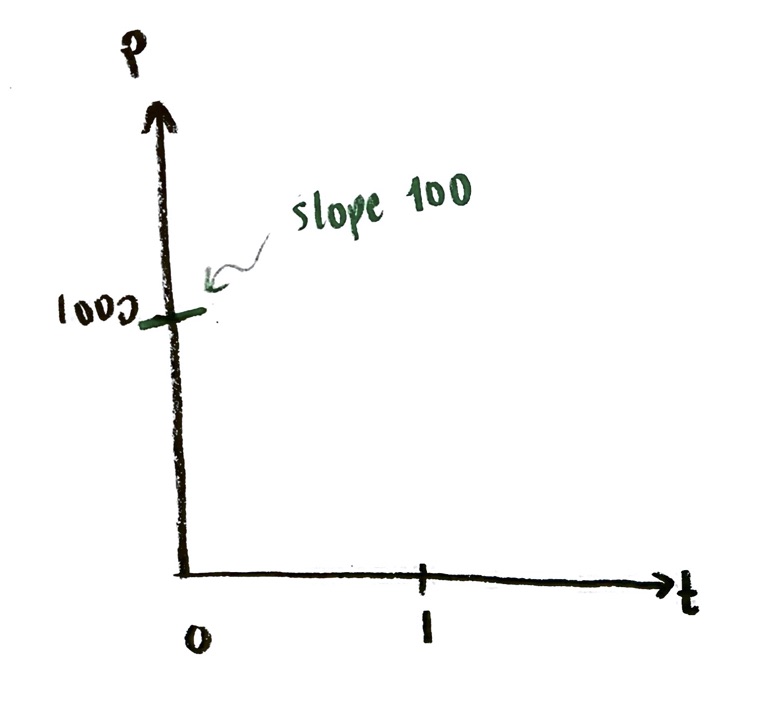
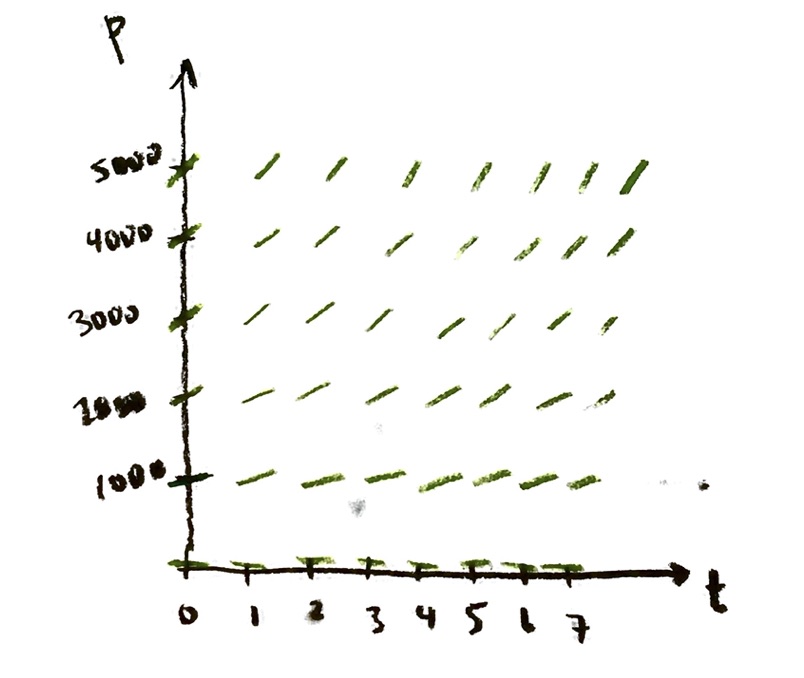
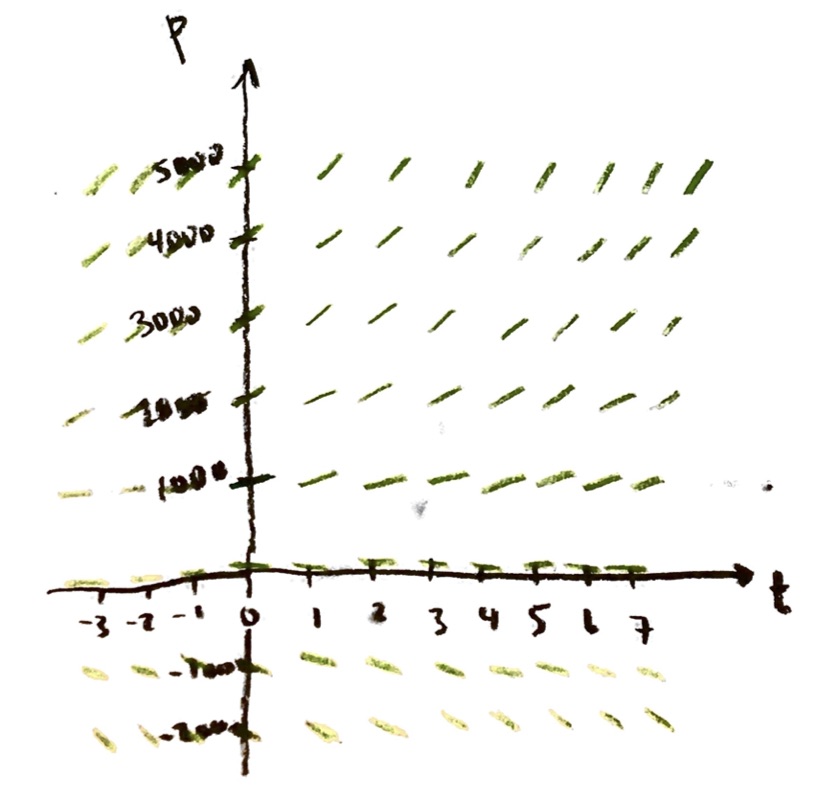
We have studied the “exponential growth” differential equation at some length now:
$\dfrac{\mathrm{d}P}{\mathrm{d}t}=rP$, where $r$ is a constant.
This models unrestricted continuous population growth. (It also models nuclear decay, and a number of other things.)
Since I don’t necessarily want to be modeling population with time, let’s switch to more generic variables y and x:
$\dfrac{\mathrm{d}y}{\mathrm{d}x}=ry$, where $r$ is a constant.
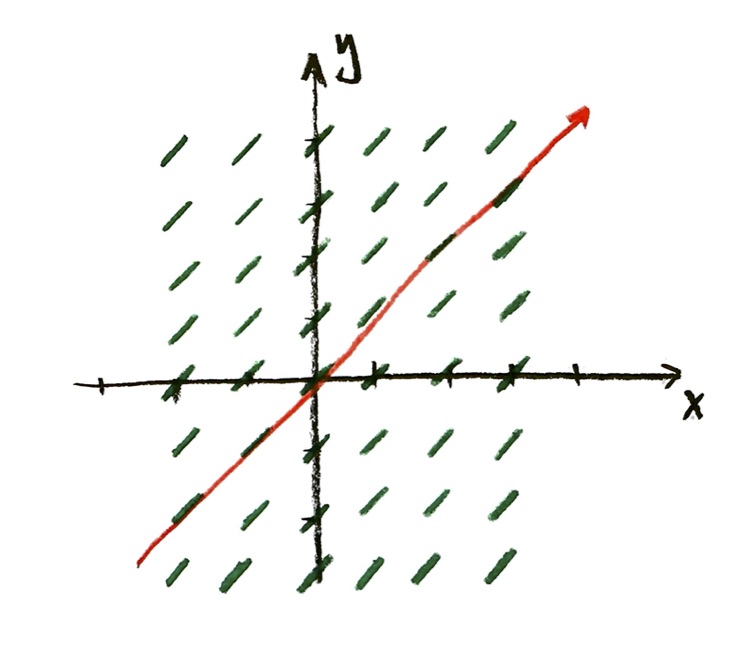
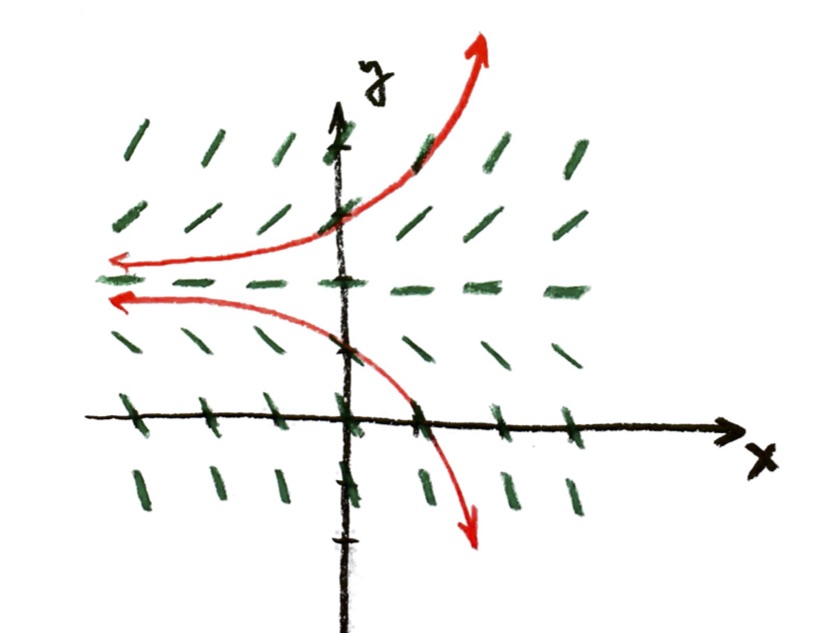
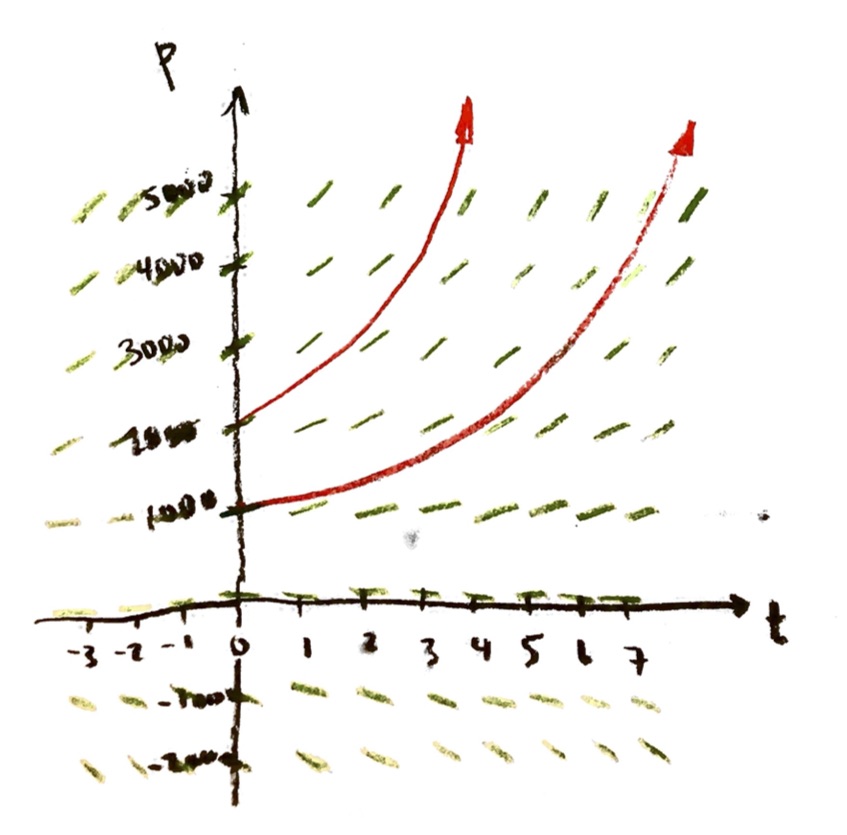
Taking r=1, we drew the slope field. Assuming that we start at y=1 when x=0, we found an equation for the solution curve:
$y=e^x$
where $e\doteq2.7182818284590452353602874713526624977572470936999595749669676277240766303535475945713821785251664274274663919320030599218174135\ldots$. The number $e$ is found by the formula
$e=\lim_{\Delta t\to 0}\left(1+\Delta t\right)^{\frac{1}{\Delta t}}$;
we gave an argument for why that was so in class. (In case you’re curious, here is the number e to one million decimal places!)
The equation $y=e^x$ is the solution (i.e. equation of the solution curve) for the problem
$\dfrac{\mathrm{d}y}{\mathrm{d}x}=y$, and y=1 when x=0.
Let’s elaborate and expand on this a bit.
power series for exponential function
In class, I described trying to solve the the differential equation
$\dfrac{\mathrm{d}y}{\mathrm{d}x}=y$, and y=1 when x=0,
by means of an “infinite polynomial”, or power series. I started off looking for a solution with y as a power of x, $y=x^n$. That can’t possibly work, because the differential equation says that the derivative of the function y with respect to x should equal the original function I started with! If $y=x^n$, then
$\dfrac{\mathrm{d}y}{\mathrm{d}x}=nx^{n-1}$,
and there is no way that $x^n$ and $n x^{n-1}$ can be equal functions. (Their numerical values could be equal for some particular values of x, certainly. But the differential equation is saying that the two formulas should be equal for all values of x—that is, that they should define the same solution curve—and that can’t possibly happen for $x^n$ and $n x^{n-1}$.)
I run into the same problem with any polynomial formula for $y$, because, for example, if $y=x^{10}+3x^5-x^3$, then the highest power of $x$ in the derivative of $y$ would be an $x^9$; therefore, the formula of the derivative cannot equal the formula of the original $y$.
But we wouldn’t run into this problem if $y$ was a “polynomial” that did not have a highest power!
So, I assume that the unknown function y of x I’m looking for can be written in the form
$y=a_0 + a_1x + a_2 x^2 + a_3 x^3 + a_4 x^4 + a_5 x^5 + a_6 x^6 + a_7 x^7 +\dotsb$,
where the $a_0$, $a_1$, $a_2$, . . . are some unknown numbers. Note that at this point, I do not know whether this is actually going to work! I have no particular reason to believe that the solution curve $y$ can be written this way. I’m just going to try it, and see if it works. I might run into a roadblock, like I did when I tried ordinary polynomial formulas; in that case, I’d have to back up and try something different. Or, it might work out.
(If it does work out, then I don’t have to worry if the path I took to get to the answer was kind of mysterious or illegal. The problem is to find a solution of the differential equation. If you can cook up an answer some crazy way, like seeing it in a dream, that’s fine: as long as you can show it satisfies the equation, it’s got to be correct!)
Alright: suppose the function y of x is given by this “infinite polynomial” (power series),
$y=a_0 + a_1x + a_2 x^2 + a_3 x^3 + a_4 x^4 + a_5 x^5 + a_6 x^6 + a_7 x^7 +\dotsb$,
and suppose that it satisfies the differential equation
$\dfrac{\mathrm{d}y}{\mathrm{d}x}=y$, and y=1 when x=0.
Let’s see if we can find the constants $a_0$, $a_1$, $a_2$, . . . based on these assumptions.
Problem: Power Series for $e^x$ (see below for answers!)
a. Use the initial condition, y=1 when x=0, to determine one of the constants.
b. Find the derivative of the power series formula representing the function $y$. (Your answer should be another infinite power series.)
c. Suppose that $\dfrac{\mathrm{d}y}{\mathrm{d}x}=y$. This should mean that two infinite power series are equal, as functions. That is, the numbers in front of each power of x should be the same in both formulas. Use this to give an infinite list of conditions on the $a_i$ constants.
d. Solve for all the $a_i$!
e. Put your answers back in the assumed series for y, to obtain a final formula for y.
Answers:
a. Setting y=1 and x=0 into the assumed formula for y, we end up with
$1=a_0+a_1(0)+a_2(0)+a_3(0)+\dotsb$
so we get $a_0=1$. We know one of the constants now!
b. Using what we did in Problem Sets 1 and 2, the derivative of
$y=a_0 + a_1x + a_2 x^2 + a_3 x^3 + a_4 x^4 + a_5 x^5 + a_6 x^6 + a_7 x^7 +\dotsb$,
is
$\dfrac{\mathrm{d}y}{\mathrm{d}x}=a_1 + 2a_2 x + 3a_3 x^2 + 4a_4 x^3 + 5a_5 x^4 + 6a_6 x^5 + 7a_7 x^6 +\dotsb$.
c. I am assuming that the only way these two functions, $y$ and $\dfrac{\mathrm{d}y}{\mathrm{d}x}$, can be equal, is if they have exactly the same formula; that is, if the number in front of $x^n$ is the same in each formula for every power $n$. (I’m making an assumption here; if we were doing things more carefully, I’d need to prove that is actually true.)
This only works if we have:
$a_1=a_0$, $2a_2=a_1$, $3a_3=a_2$, $4a_4=a_3$, $5a_5=a_4$, . . .
d. Let me write these slightly differently:
$a_1=a_0$, $a_2=\frac{1}{2}a_1$, $a_3=\frac{1}{3}a_2$, $a_4=\frac{1}{4}a_3$, $a_5=\frac{1}{5}a_4$, . . .
But we know $a_0=1$! So we can solve these “recursively”:
$a_1=a_0=1$
$a_2=\frac{1}{2}a_1=\frac{1}{2}(1)=\frac{1}{2}$
$a_3=\frac{1}{3}a_2=\frac{1}{3}\frac{1}{2}=\frac{1}{3\cdot 2}$
(That dot in the last denominator is a “times”. I’m writing $a_3$ as $\frac{1}{3\cdot 2}$ rather than $\frac{1}{6}$, because I want to be able to see the pattern more easily. But it is just $a_3=\frac{1}{6}$.)
$a_4=\frac{1}{4}a_3=\frac{1}{4}\frac{1}{3}\frac{1}{2}=\frac{1}{4\cdot 3\cdot 2}$
$a_5=\frac{1}{5}a_4=\frac{1}{5}\frac{1}{4}\frac{1}{3}\frac{1}{2}=\frac{1}{5\cdot 4\cdot 3\cdot 2}$
Now you can see the pattern:
$a_n=\frac{1}{n\cdot (n-1)\cdot \dotsb \cdot 4\cdot 3\cdot 2\cdot 1}$
(I put the “times 1” at the end just to make the pattern more consistent looking. Of course it doesn’t change anything.)
Since this pattern happens a lot in math, we have a name (“factorial”) and a symbol for it: for any whole positive number n, we define
$n!=n\cdot (n-1)\cdot \dotsb \cdot 4\cdot 3\cdot 2\cdot 1$.
e. Putting these back into the formula for y, we get
$y=1+x+\frac{1}{2!}x^2+ \frac{1}{3!}x^3+\frac{1}{4!}x^4+\frac{1}{5!}x^5+\dotsb$
Since we already know that $y=e^x$, we get
$e^x=1+x+\frac{1}{2!}x^2+ \frac{1}{3!}x^3+\frac{1}{4!}x^4+\frac{1}{5!}x^5+\dotsb$
Checking the solution
Remember that I assumed that y could be written as
$y=a_0 + a_1x + a_2 x^2 + a_3 x^3 + a_4 x^4 + a_5 x^5 + a_6 x^6 + a_7 x^7 +\dotsb$
for some constants $a_0$, $a_1$, $a_2$, . . . And, pushing through with a spirit of hope, we found that if that is true, then in fact
$y=1+x+\frac{1}{2!}x^2+ \frac{1}{3!}x^3+\frac{1}{4!}x^4+\frac{1}{5!}x^5+\dotsb$
This should supposedly be a solution to the problem
$\dfrac{\mathrm{d}y}{\mathrm{d}x}=y$, and y=1 when x=0.
But is it? The path I took to get here is a little suspicious. Let’s try to check this.
Problem: Checking power series solution for exponential function
a. With y given by the formula above, check that y=1 when x=0. (This shouldn’t be hard!)
b. Find the derivative of y with the formula given above. Does taking the derivative give you back the original formula, as it was supposed to?
There is another thing to worry about. Remember when we found an infinite series for the function $1/(1+x)$, which came out
$\dfrac{1}{1+x}=1-x+x^2-x^3+x^4-x^5+x^6-x^7+\dotsb$?
If you recall, this formula worked out great if the x value was small enough, specifically $-1<x\leq 1$. But it made no sense for larger values.
Something similar can happen with this technique for solving a differential equation: we can get a formula which is correct, but only in a limited range.
Happily, as it turns out, our power series for $y=e^x$ actually gives correct answers for all values of $x$. (If you take a more advanced course, we would prove that.)
Solution with different initial conditions
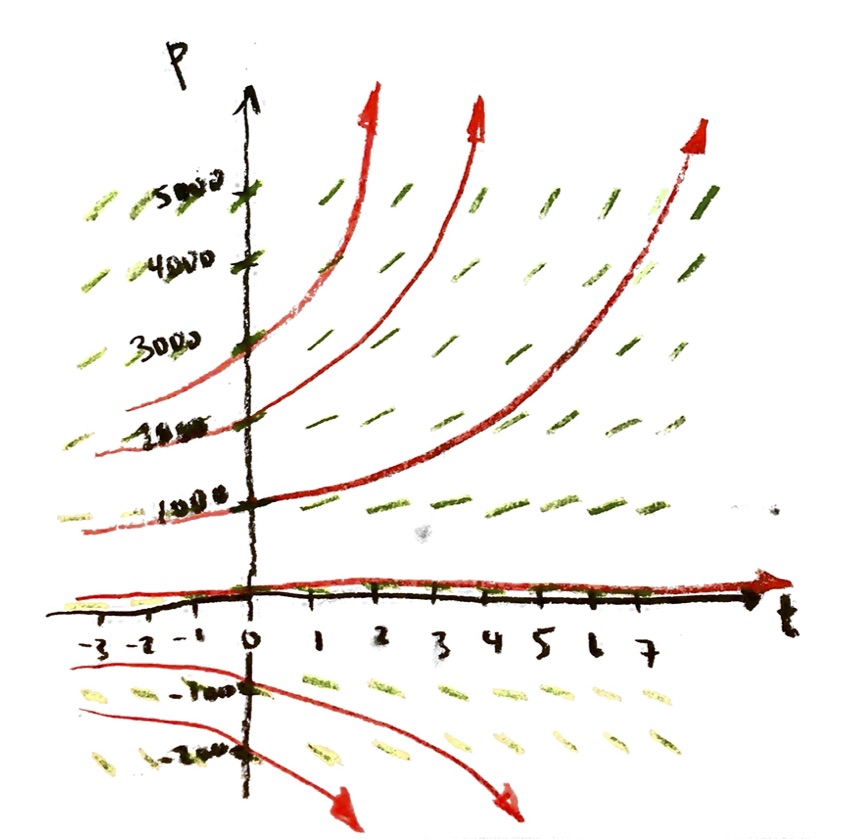
Suppose that instead of starting with y=1 when x=0, we started with some other value $y=y_0$ at x=0. (In the population model, the value of $y_0=P_0$ would correspond to our starting population at time t=0.)
There are two ways we could find the formula for the solution. First way: we could go back to the same procedure we did above, just with a different starting point. It will be good practice to work this out yourself:
Problem: Exponential differential equation with different initial condition
As before, assume that we are trying to solve $\dfrac{\mathrm{d}y}{\mathrm{d}x}=y$, but now we are assuming $y=y_0$ when $x=0$. As before, assume that $y$ can be written in the form $y=a_0 + a_1x + a_2 x^2 + a_3 x^3 + a_4 x^4 + a_5 x^5 + a_6 x^6 + a_7 x^7 +\dotsb$.
a. Use the initial condition to determine the $a_0$. (“Determine” means it will be in terms of $y_0$.)
b. Repeat the process that you did before, to get $a_1$ in terms of $a_0$, to get $a_2$ in terms of $a_1$, etc etc. It should all work out very similarly, except for a $y_0$ in each of your formulas.
c. Put the answers all back into $y=a_0 + a_1x + a_2 x^2 + a_3 x^3 + a_4 x^4 + a_5 x^5 + a_6 x^6 + a_7 x^7 +\dotsb$, to get the formula for y. (It will involve $y_0$.)
d. If you haven’t already, try to simplify y. (Hint: You should be able to write it so there is only one $y_0$ in your entire formula.)
e. Compare to the answer you got before, when $y_0=1$. Can you write this solution in terms of the earlier solution?
The answer to the last part should be the following: you will end up with
$y=y_0 e^x$.
This solves the differential equation $\dfrac{\mathrm{d}y}{\mathrm{d}x}=y$, with the initial condition $y=y_0$ when $x=0$.
There is a second way: we can make a change of variable. This is what Thompson calls a “useful dodge”. Here’s how it works. Suppose we want to solve the differential equation
$\dfrac{\mathrm{d}y}{\mathrm{d}x}=y$, with initial condition $y=y_0$ when $x=0$.
I introduce a new variable $u$, which is defined by $y=y_0 u$. Since $y_0$ is a constant, if I vary u a little bit to $u+\,\mathrm{d} u$, then the corresponding $\mathrm{d} y$ is given as follows:
$y+\mathrm{d} y = y_0\left(u+\mathrm{d}u\right)$
$y+\mathrm{d} y = y_0 u+y_0\mathrm{d}u$
$\mathrm{d} y = y_0\mathrm{d}u$
So, dividing by $\mathrm{d}x$ on both sides, we get
$\dfrac{\mathrm{d} y}{\mathrm{d} x}=y_0\dfrac{\mathrm{d}u}{\mathrm{d} x}$.
(We could have also got the same result by the derivative rules.)
Substituting this, and $y=y_0 u$, into the differential equation $\dfrac{\mathrm{d}y}{\mathrm{d}x}=y$, we get the differential equation
$y_0\dfrac{\mathrm{d} u}{\mathrm{d} x}= y_0 u$,
from which I can cancel the $y_0$ on both sides, and get
$\dfrac{\mathrm{d} u}{\mathrm{d} x}= u$.
That’s exactly the same differential equation as I started with for y! What is the initial condition? Well, when $x=0$, we have $y=y_0$. Then, putting this into $y=y_0 u$, we get $y_0=y_0 u$, so $u=1$. That is, the initial condition is, when $x=0$, we have $u=1$. So our problem is:
$\dfrac{\mathrm{d} u}{\mathrm{d} x}= u$, and $u=1$ when $x=0$.
That’s exactly the problem we started with!! So it has the same solution:
$u=e^x$.
I want to go back to the original variable, so I’ll multiply both sides by $y_0$:
$y_0 u = y_0 e^x$.
Using $y=y_0 u$, we get:
$y=y_0 e^x$.
That solves the problem
$\dfrac{\mathrm{d}y}{\mathrm{d}x}=y$, and y=y_0 when x=0,
and it agrees with the solution we found the first way.
Problem: Checking the solution again
Check this directly. That is, start with $y=y_0e^x$. Knowing that the derivative of $e^x$ is $e^x$, use this to find the derivative of $y=y_0e^x$. Check that it satisfies the differential equation $\dfrac{\mathrm{d}y}{\mathrm{d}x}=y$. Also, substitute in $x=0$ to check that then $y=y_0$.
Solution with a different rate
We had started with the exponential growth differential equation,
$\dfrac{\mathrm{d}P}{\mathrm{d}t}=rP$, and $P=P_0$ when $t=0$.
where $r$ is some constant. The last little while, I’ve been assuming $r=1$ to make things simple. But now it’s time to put the $r$ back in.
(I am going to change from $y$ and $x$ back to $P$ and $t$ for these problems, just for variety. It doesn’t really change anything.)
Again, there are two ways to proceed! First way, do the same procedure that we started with from the beginning, with the infinite series:
Problem: Exponential growth with rate r, by infinite series
Suppose we want to solve $\dfrac{\mathrm{d}P}{\mathrm{d}t}=rP$, and $P=P_0$ when $t=0$. Start by assuming that
$P=a_0+a_1 t + a_2 t^2 + a_3 t^3 + a_4 t^4+\dotsb$.
a. Find the value of $a_0$, in terms of $P_0$.
b. Find the derivative of the power series representing $P$.
c. Find $rP$, where you will substitute in the power series for $P$, and multiply all the terms through by $r$.
d. Setting $\frac{\mathrm{d}P}{\mathrm{d}t}=rP$, you have two power series that are supposed to be equal. Use this to get conditions on the $a_1$, $a_2$, $a_3$, . . .
e. Solve the conditions to find the values of the $a_1$, $a_2$, $a_3$, . . .
f. Put the answer back in the power series, to find the formula for P. Simplify it as much as you can.
I won’t give the answers right away, but you will be able to check your answers against the second method.
The second method is to make a change of variable (the “useful dodge”):
Problem: Exponential growth with rate r, by change of variable (see below for answers!)
Introduce a new variable $s$, defined by $s=rt$.
a. Find the relationship between $\mathrm{d} s$ and $\mathrm{d}t$. (Remember that $r$ is a constant.)
b. Substitute this into the differential equation $\frac{\mathrm{d}P}{\mathrm{d}t}=rP$, to get a differential equation for $P$ as a function of $s$ (that is, eliminate the variable t).
c. Recognize this as a differential equation you can solve! Check the initial condition, and write out the answer for P as a function of s.
d. Make a substitution to write P as a function of t, which is the final answer.
Answers:
a. $\mathrm{d} s = r\,\mathrm{d} t$.
b. There’s different ways to do the algebra. I find it convenient to rewrite the differential equation as
$\mathrm{d}P=rP\,\mathrm{d}t$.
Then I can identify $r\,\mathrm{d} t$ as $\mathrm{d} s$, so
$\mathrm{d}P=P\,\mathrm{d}s$,
or
$\dfrac{\mathrm{d}P}{\mathrm{d}s}=P$.
c. This is just the original differential equation! And the initial condition is the same, too, because when $s=0$, we have $t=0$, so $P=P_0$ when $s=0$. So the solution is
$P=P_0 e^s$,
as in the previous section.
d. Now, we can put back $s=rt$, to find
$P=P_0 e^{rt}$
as the solution of
$\dfrac{\mathrm{d}P}{\mathrm{d}t}=rP$, and $P=P_0$ when $t=0$.
Nice!
You can use this to check your answer by the first method. For the first method, you should have gotten
$P=P_0\left(1+rt+\frac{1}{2!}r^2t^2+\frac{1}{3!}r^3t^3+\frac{1}{4!}r^4t^4+\dotsb\right)$
You can rewrite this as
$P=P_0\left(1+(rt)+\frac{1}{2!}(rt)^2+\frac{1}{3!}(rt)^3+\frac{1}{4!}(rt)^4+\dotsb\right)$
and that is the same as substituting (rt) in everywhere for the original exponential series we got. That is,
$P=P_0e^{rt}$,
which agrees with the second method.
Trigonometric functions
Now, I want to refer back to what we did on trigonometric functions, in Problem Set #6, Problems #5 and 6. First, a quick reminder of the setup. I was starting with a circle of radius 1, whose center was at the origin (0,0) of an x-y coordinate system. I was starting at the point (1,0) on the circle, and then traveling a distance s counter-clockwise along the edge of the circle.
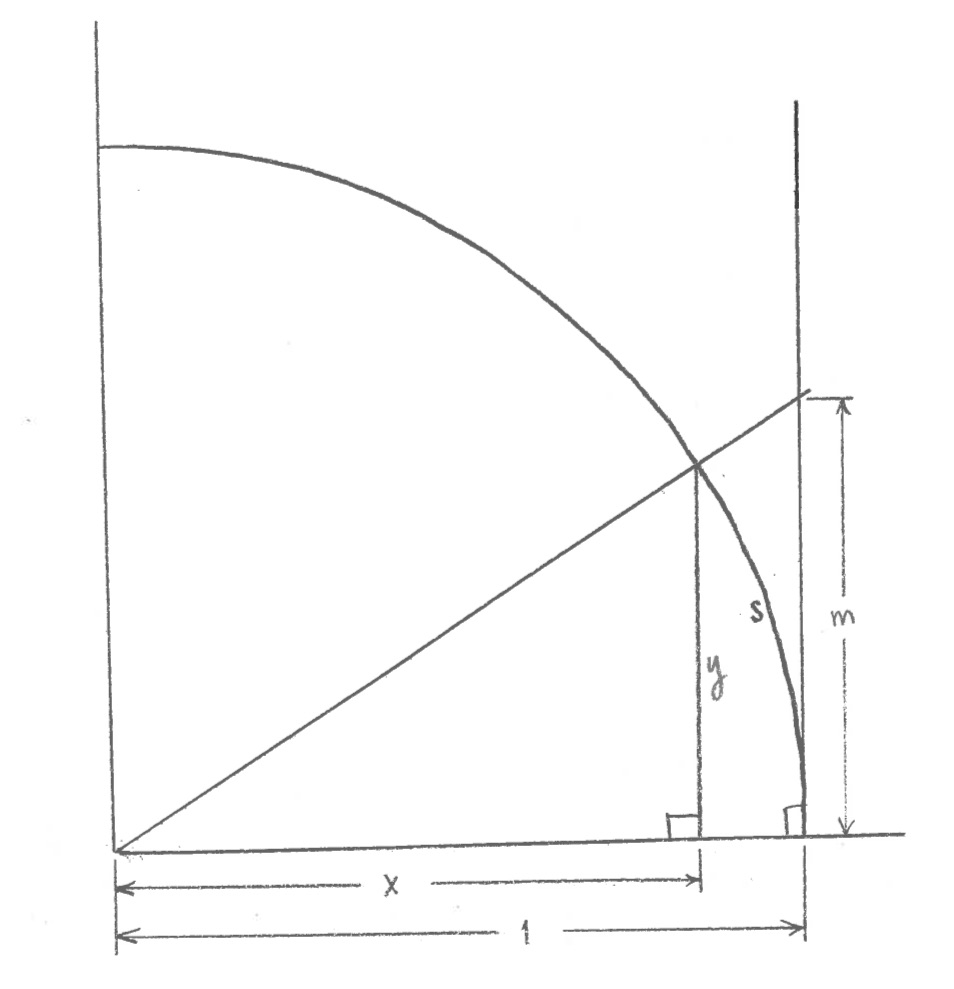
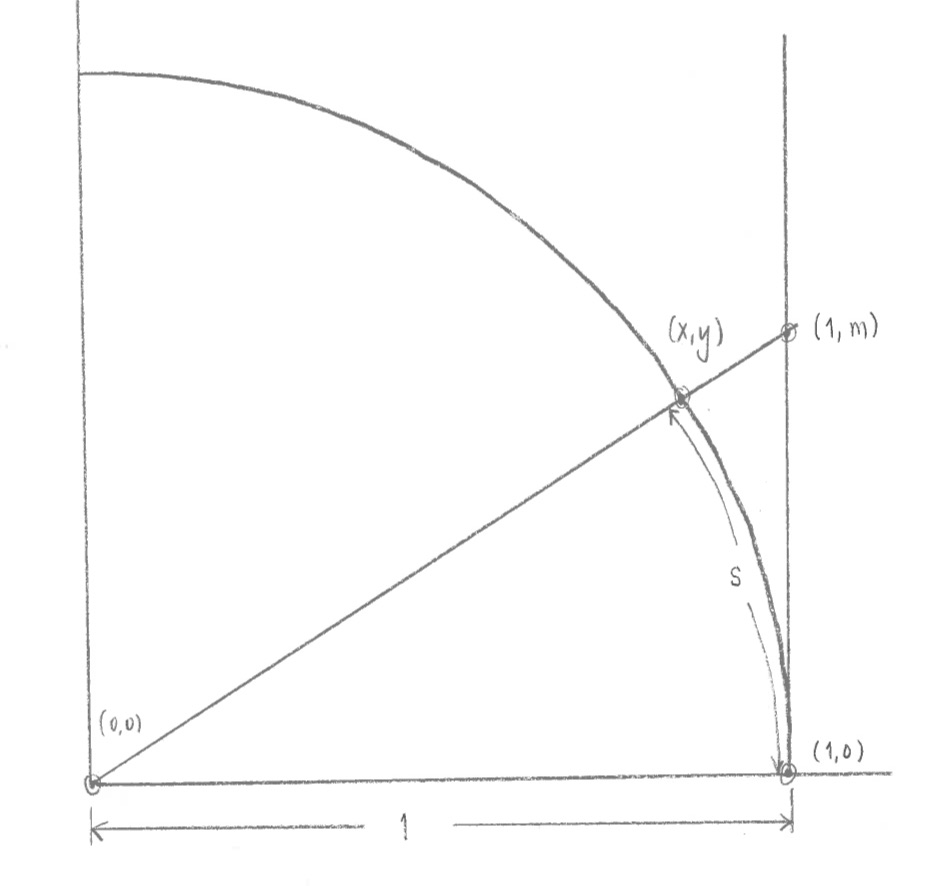
After traveling a distance s counter-clockwise along the edge of the circle, starting at (1,0), I end up at a point (x,y). I wanted to find formulas for x and y in terms of s. Or similarly, to find formulas for s in terms of x or in terms of y.
Now, there is a trig answer:
$x=\cos s$ and $y=\sin s$.
You could either prove these facts, assuming the definitions you learned in high school for cosine and sine (based on right triangles), and using the diagram above. Or, another way of looking at things is to define the functions cosine and sine by this diagram, so that the two formulas above are true by definition. This is the way I will think of it. (Then the high school definitions of cosine and sine follow from this definition.)
Note that this doesn’t totally answer my question: I do not have any way of calculating x or y if I know s. Saying that $x=\cos s$ is just a way of naming the relationship. If I have a calculator, and I know s, I can find x; but how is the calculator doing that??
In what follows, I’m going to look for an actual formula for x and y in terms of s, which will actually let me find the x and y numerically if I know the s. (In another way of speaking, it will give us an actual formula for the cosine and sine functions.)
Remember also that I increased the s slightly to $s+\,\mathrm{d}s$, which changed the point $(x,y)$ to the point $(x+\,\mathrm{d}x,y+\,\mathrm{d}y)$. In Problem Set #6, I asked you to try to figure out $\mathrm{d}x$ and $\mathrm{d}y$ in terms of $\mathrm{d}s$. Here were the answers:
$\mathrm{d} x = -y \,\mathrm{d}s$
$\mathrm{d} y = x \,\mathrm{d}s$.
That translates to two differential equations:
$\dfrac{\mathrm{d} x}{\mathrm{d}s} = -y $
$\dfrac{\mathrm{d} y}{\mathrm{d}s} = x $.
There are two unknown functions, x and y, which each depend on the variable s. Their differential equations are interlocked: the derivative of the unknown function y equals the unknown function x; the derivative of the unknown function x equals the negative of the unknown function y.
We also have initial conditions: looking at the diagram, if $s=0$, then we are at the point $(1,0)$, which means $x=1$ and $y=0$ when $s=0$.
We can attempt to solve these differential equations by the same method as before, with the infinite power series. There are now two unknown power series:
$x=a_0 + a_1 s + a_2 s^2 + a_3s^3 + a_4 s^4 + a_5s^5 + a_6 s^6 + \dotsb$
$y=b_0 + b_1 s + b_2 s^2 + b_3s^3 + b_4 s^4 + b_5s^5 + b_6 s^6 + \dotsb$
Here, the $a_0$, $a_1$, $a_2$ . . . and the $b_0$, $b_1$, $b_2$ . . . are all unknown constants. (These are different from the $a_0$, $a_1$, $a_2$ from before for the exponential function.)
We can use initial conditions and differential equations to solve for all these unknown constants:
Problem: Power Series for sine and cosine
a. Use the initial conditions to find the values of $a_0$ and $b_0$.
b. Find the derivative of the power series for $x$, and of the power series for $y$.
c. Find the power series for $-y$. (Just multiply through the minus sign times every coefficient of the power series for $y$.)
d. Now, use the equalities $\frac{\mathrm{d} x}{\mathrm{d}s} = -y $ and $\frac{\mathrm{d} y}{\mathrm{d}s} = x $ to say that two pairs of infinite power series should be equal. Use that to get two series of conditions that relate the $a_1$, $a_2$, $a_3$ . . . and the $b_1$, $b_2$, $b_3$, . . .
e. Solve these equations, to find the values of all the $a_1$, $a_2$, $a_3$ . . . and the $b_1$, $b_2$, $b_3$, . . .
f. Put the values of the $a_1$, $a_2$, $a_3$ . . . and the $b_1$, $b_2$, $b_3$, . . . back into the power series for x and y, to get formulas for x and y in terms of s.
Now that we have the solutions, this gives us an infinite power series for $x= \cos s$ and for $y=\sin s$. Once you have a tentative answer, you can check it:
Problem: Checking solutions for power series for sine and cosine
Take your power series for x, and take its derivative. It should come out to be the same as the negative of the power series for y. Does it? If not, you might need to simplify; or you might need to correct an error from the previous problem. Similarly, take your power series for y, and take its derivative; it should come out to be the same as your power series for x.
I don’t want to put the answers here, to give you a chance to work them out. However, if you look up “cosine power series”, you can find the answer.
It’s also interesting to check these answers graphically:
Problem: Graphing the power series for sine and cosine
Use Desmos to graph the function $y=\cos x$. (To use the grapher, we have to change our variable s to x, and x to y, which is maybe a little confusing!) Now, on the same axes, graph $y=1-(1/2)x^2$, which should be the first two terms of your power series for cosine (again, switching the variable s to x). There should be a nice fit near x=0 (s=0)! This is the “best fit parabola” to the function cosine at s=0. Now, graph the functions you get when you add in more and more terms of the power series. If everything is right, you should see these polynomials fitting more and more closely the cosine function.
Oscillations
I won’t quite get to the Kepler problem in this problem set, although I’ll try to show how to solve it in a final optional lecture after this one. However, I can show you how these ideas come up in physics problems, by using a simpler physics problem.
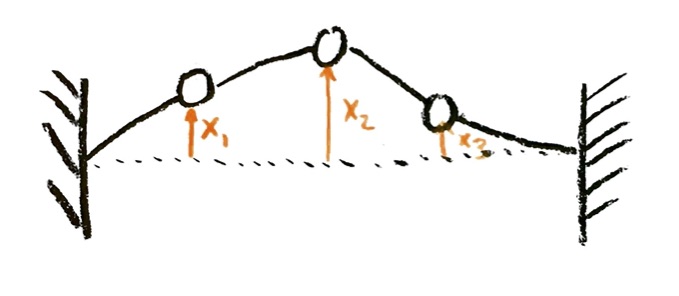
Let’s say we have a mass on a spring. I assume that the mass can only move in one direction, let’s call it the x-axis. I set up my coordinate so that the spring is at rest (not stretched or squeezed) when x=0. Then x is the displacement from rest. If $x>0$, the spring is stretched, and the mass experiences a force in the negative direction; if $x<0$, the spring is squeezed, and the mass experiences a force in the positive direction. In either case, the force is pushing the mass back towards x=0; such a force is called a restoring force, and x=0 is called a stable equilibrium.
The simplest model is to assume that the restoring force is simply proportional to the displacement from equilibrium:
$F=-kx$,
where $x$ is the displacement from equilibrium, and $k$ is some constant. Nearly any force approximately obeys this assumption for small enough displacements. So we can use it for a mass on a spring, but also for a swinging pendulum, or a swaying bridge: nearly any situation where there is a stable equilibrium and a restoring force, and where the displacements are not too large.
Using Newton’s law,
$a=\dfrac{F}{m}$,
we find that
$a=-\dfrac{k}{m} x$.
The acceleration, by definition, is the derivative of the velocity with respect to time; and the velocity, by definition, is the derivative of the displacement with respect to time. We have two unknown functions of time $t$, the position $x$ and velocity $v$, and we get two interlocked differential equations for those unknown functions:
$\dfrac{\mathrm{d}v}{\mathrm{d} t} = -\dfrac{k}{m} x$
$\dfrac{\mathrm{d}x}{\mathrm{d} t} = v$
This is suspiciously similar to our situation with the cosine and sine functions!! That is not a coincidence.
As before, we could take two strategies: we could start over with the unknown power series, and solve as before. We would get very similar answers to what we got for cosine and sine, with some $\frac{k}{m}$ factors thrown in. Or, second strategy, we could change variables. I will just outline the second strategy here.
Problem: Solving harmonic oscillator (partial answers below)
a. To start off with, let’s suppose that $\frac{k}{m}=1$. Let’s also suppose that the initial condition is $x=1$, and $v=0$, when $t=0$. In this case, compare to the differential equations we got before for the unit circle, for x and y in terms of s. They should be very similar! Use this similarity to write the position x and velocity v as functions of t. The functions should involve cosines and/or sines.
b. Does your answer make physically?
c. Now, if $\frac{k}{m}\neq 1$, we can try the change of variables trick. There’s something a little sneaky this time: I’m going to make a new variable s to replace t, by $s=\sqrt{\frac{k}{m}}t$, and I’m going to make a new variable w to replace v, by $v=\sqrt{\frac{k}{m}}w$. I’m going to leave x as just x. (If I had more time, I could explain where I got these!!) Use these equations to find the relation of $\mathrm{d}s$ and $\mathrm{d}t$, and also the relation of $\mathrm{d}v$ and $\mathrm{d}w$. Put the relations into the differential equations. You should find, once everything is simplified, that you get the equations
$\dfrac{\mathrm{d}w}{\mathrm{d} s} = – x$
$\dfrac{\mathrm{d}x}{\mathrm{d} s} = w$
d. Assuming we again start with $x=1$ and $v=0$ when $t=0$, use that to give initial conditions for $x$ and $w$, when $s=0$. Then give the solutions to the differential equations for x and w, as functions of s.
e. Finally, substitute back in, to find the position x and velocity v as functions of time t.
Something that is remarkable here is that the differential equation for oscillation is very physically natural. If we try to solve this differential equation, we get the power series for cosine and for sine (for the position and velocity). So, even if we never cared about triangles at all, the cosine and sine functions would be forced on us by physics and differential equations. In fact, this is the more calculus-style way of defining cosine and sine: we define them to be the solution of the differential equations I wrote earlier. Then we would use that to prove that they in fact give the x and y coordinates of that point on the circle, and use that to finally say they happen to equal opposite/hypotenuse and adjacent/hypotenuse.
And finally, some magic
I want to finish with a formula that I think is kind of magical. It is not just a nice mathematical formula though; it is very important in engineering and physics, for example. It will give a simpler way of solving the oscillation problem we just did, and it will allow for oscillations with damping (though we won’t have time to get to that: take ordinary differential equations next term!).
First, I need to remind you / tell you about complex numbers. You may recall that a negative number cannot have a square root. There cannot be any normal number x such that
x times x equals -1,
because (positive)*(positive)=positive, and (negative)*(negative)=positive. So $\sqrt{-1}$ has no meaning in ordinary (“real”) numbers. However, as early as the 1400s, people identified instances where having a square root for negative numbers would be mathematically convenient. It turns out that many things in mathematics (and physics) work out much more nicely if you allow for negative numbers to have square roots. This requires us to expand our concept of “number” to “complex numbers” (which contain the real numbers). Complex numbers turn out to be inextricably part of quantum mechanics, which makes them part of reality! They are not just a convenient mathematical invention.
We simply declare the existence of a new number, which we call $i$, which has the property that
$i^2=-1$.
This means $\sqrt{-1}=\pm i$. Similarly, $\sqrt{-4}=\pm 2 i$. (You can check these claims by squaring $i$ and $-i$, and seeing you get -1 in both cases; or squaring $2i$ and $-2i$, and seeing that you get -4 in both cases.)
A complex number is any number I can make by combining real numbers with any expressions involving $i$. It turns out that the parts involving $i$ can always be greatly simplified; in fact, any algebraic mess you can make with real numbers and $i$s can always be boiled down to $x+iy$, for some real numbers $x$ and $y$.
As an illustration, try the following:
Problem: Powers of $i$
a. Simplify $i^3$. (Remember that $i^3=i\cdot i\cdot i$.)
b. Simplify $i^4$. (Hint: this one should come out to be very simple!!)
c. Simplify $i^5$, $i^6$, $i^7$, $i^8$, $i^9$.
d. What’s the pattern?
e. Simplify $i^{403}$.
If this was specifically about complex numbers, I would go on to tell you how to simplify things like $1/(1+i)$ or $\sqrt{i}$. But what you did in the problem is enough to tell you the magical thing I want to tell you.
Here’s what I want you to try: to simplify the function $y=e^{ix}$, where $i^2=-1$ as above.
Problem: The function $y=e^{ix}$
a. Recall the power series for $y=e^x$ that you found, at the beginning of this problem set. In that series, substitute in $ix$ every place there is an $x$, to obtain the series for $y=e^{ix}$. (Be sure to put the $ix$ in as one unit in place of the $x$, with parentheses as needed. For example, if there is an $x^2$ in the power series for $y=e^x$, replace that $x^2$ with $(ix)^2$, so that that $i$ will get squared as well.
b. Replace $(ix)^2=i^2x^2$, $(ix)^3=i^3x^3$, etc.
c. Now, use the simplifications you made for powers of $i$.
d. You will find that half the terms have an $i$, and half do not. Collect all the terms without any $i$ in them all first, and then collect all the terms that do have an $i$ in them afterwards. If everything is correct, you should be able to factor out a common “$i$” out of all the latter half of the terms: do so.
e. Now, you should have one power series without any $i$, plus $i$ times a second power series. You should recognize each of those power series from a previous question! Use what those power series represent, to write $e^{ix}$ in terms of other known functions.
I don’t want to write the answer here, because I don’t want to spoil the punch line. But if you are stuck, and want to see what answer I am aiming for, or you want to check your answer, google the term “Euler’s formula” and you’ll see what I’m talking about. (There are actually a bunch of different things called “Euler’s formula”—he did a lot of formulas—but the first hit should be the formula I’m talking about here.)
Conclusion
There is so much more I want to tell you about! We’ve just started on all the cool things there are in calculus. But this is a good stopping point for this term: I think, if you’re caught up till now, then you should hopefully be able to do most of this problem set before the end, and be able to see a nice wrapping-up point.
If I have the time and energy, I will post an “epilogue” problem set, in which I will try to show you some of the cool things I have left out. In particular, I had promised you a derivation of Kepler’s laws. We’re nearly there (so close!), but I don’t want to overwhelm you; so I’ll put those in the optional “epilogue” (which I hope I’ll have the energy to write!). Either way, I’ll be giving you some references for further reading.