This will be a combination of written lecture and problem set. I’ll discuss some applications of eigenvalues, and integrate that with suggested problems to try.
Three comments:
- There are more problems here than you can realistically do. There are many of them, and they are open-ended. I am not expecting you to do them all. Pick one problem (or maybe two), and do that problem in as much depth as you have time for.
- In fact, I mentioned at the beginning that you could do a project for this course if you choose. Some of the problems here are open-ended enough that they would make good projects, which you could concentrate mostly on for the rest of the term if you wanted.
- On the other hand, because this lecture focuses on applications, most of the problems are for those of you who are interested in applications and computing. If you are mostly interested in theory, take a look at the questions on Fibonacci numbers and on Spectral Graph Theory; those have some quite interesting theory sides. (The other applications involve a lot of theory too!) But if you are mostly interested in theory, and don’t find any questions to your interest in this problem set, it is OK to skip it entirely; I will have more theory problems on the next problem set that you can do instead!
Google PageRank
We discussed this in class some, so I’ll be brief. Google has two problems in developing search:
- Collecting all the information and storing it, particularly all occurences of keywords, so you can create a list of all websites with a given search word;
- Ranking those search results, so you can get to the most relevant and important websites.
The first problem is largely a (difficult and interesting!) coding and implementation problem. The second problem has a more mathematical component to it.
The great challenge is to determine which website is most “important”, without the algorithm being able to understand the semantic content of any of the websites. (Although people have added evaluations of content to improve search, either by humans or AI, it’s not feasible to expect it for the bulk of search ranking. Most of the job needs to be automated.)
There are two basic ideas:
ignore the content entirely, and only look at the directed graph of outgoing and incoming links
This abstracts away anything about the websites. But with only this very abstracted information, what can we tell? How can we get started?
The second idea addresses this, in a self-referential way. It is that a website is important if other important websites link to it. More quantitatively:
the importance score of a website is proportional to the sum of the importance scores of all the websites that link to it
The first basic idea means that this setup is applicable to many things other than search. It has been used to analyze social networks to determine the “most important” players. In particular, it has been used to analyze terrorist networks, in which the analysts knew the number and direction of electronic messages, but nothing about the people behind the accounts. It has also been used in biology, where interactions between proteins or organisms are known without having details of the nature of the interactions.
The second basic idea is, as I said, essentially self-referential.
The problem below has several parts. Feel free to do just part; get into it in as much depth as you find interesting and have time for. (And feel free to skip it if this isn’t your interest.)
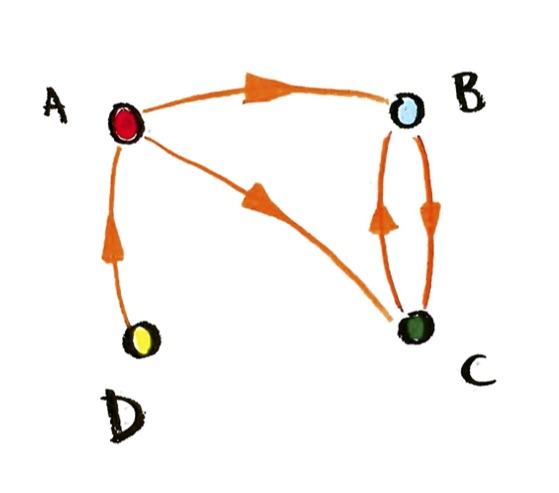
Problem: Google PageRank toy problem and set-up
a) Consider the social network that I drew above. We have people A, B, C, and D. An arrow from X to Y represents “X likes Y”. (Or you can think of A, B, C, and D as websites, and an arrow from X to Y represents “X links to Y”.) We are looking for a “popularity” or “importance” score for A, B, C, and D, obeying the rule above: the popularity score of X should be proportional to the sum of popularity scores of all those who like (link to) X. Set up equations expressing this. (Recall that two quantities P and Q are said to be proportional if it is always true that P=kQ, for some constant k.)
b) Write those equations as a matrix equation.
c) Write the matrix equation as an eigenvalue and eigenvector equation.
d) Can you find a non-zero popularity function for this example, which obeys the equation? (You can either try to solve the equations, or look at the graph and think practically.) What is the eigenvalue? Do you think this is typical?
e) Write out what the procedure and the equation would be for any given directed graph.
Problem: Google PageRank, Markov processes, and successive approximation
This is an open-ended question, which could be both theory and/or computing. Someone in class had the excellent idea of treating this problem like the Markov process we discussed earlier. We could start with some arbitrarily chosen popularity scores, and then let popularity “flow” through the network, like we did with the Markov system. The idea is that this will make our popularity scores come closer to scores which obey the condition we want. The correct popularity scores would be obtained by iterating over many time steps, to approximate the limit.
This raises two questions which you could look at:
(Theory-ish): Should this work? Can you show that the limit under this process would obey the equations we got in the previous question? Are there some limitations?
(Computing): Try some examples and see if it works!
Problem: Google PageRank existence and uniqueness
This is an open-ended, more theory type question. We have set up equations that we want the popularity/importance scores to satisfy. The questions that always come up in solving a math problem are:
– does there always actually exist a solution (i.e. a non-zero popularity score which obeys our condition)?
– if there exists a solution, is it unique? If not, can we quantify the nature of the set of solutions? (And, for a practical problem, if there are multiple solutions, can we figure out which one to choose?)
This is worth thinking about at least a little bit. It will be tough to solve in general at this point, but even if you can formulate it, that will give you some insight (and relate to other things we will do soon).
Problem: Google PageRank computing examples
This problem is a “computing” problem, and a little more open-ended. It would be interesting to generate a network, set up the matrix eigenvalue equation, and then actually compute the eigenvalues and eigenvectors, and see what the popularity scores look like. This could also give you insight into the above problems, of whether there always exists a solution and if it is unique.
Note that SciPy/SageMath have built-in functions to compute eigenvalues and eigenvectors. I would recommend starting with a small example, like the one above that we did and have some answers for. Then gradually make it bigger: maybe add some extra edges to our A, B, C, D example first. Then try to add more nodes. If you’re feeling ambitious and want larger examples, you could get the computer to randomly make some larger networks. Even if you’re not specifically interested in this sort of computing application, some computer experimentation like this can give you some intuition and insight about how eigenvalues and eigenvectors work for these sorts of matrices!
Problem: Google PageRank further reading
There are a number of good resources about this problem. For this problem, you could start working your way through this paper:
The $25,000,000,000 Eigenvector: The Linear Algebra Behind Google
The paper suggests a more refined version of what I’ve been arguing here, and answers some of the theoretical questions that I mentioned. And there are exercises! If you find this question interesting, working through this paper could be a good final project for the class, that would teach you a lot about the topics we have been working with.
Problem: Computing eigenvalues by powers of a matrix; dominant eigenvalue
In the discussion in class, it came up that for large matrices like in PageRank, the eigenvalues and eigenvectors (particularly the largest, or “dominant” eigenvalue) are often computed by taking powers of the matrix, rather than the method I described in class for small matrices. If you are interested in this topic, you can find an introduction in the first part of the following excerpt (from Kolman and Hill, Elementary Linear Algebra):
Kolman and Hill, Dominant Eigenvalue and Principal Component Analysis
Note that the section starts with the spectral decomposition! For this problem, you could work through the explanations and examples in this handout, and perhaps try a couple of exercises, depending on the depth of your interest in this topic.
Principal Component Analysis
I won’t attempt to write up an explanation here. Rather, I will refer you to some sources. Depending on your level of interest in this topic, I would recommend reading and working through these sources, trying some of the exercises, and perhaps trying an analysis on your own. This could count as a problem set or a project, depending how far you take it. But if you just want the basic idea, you could read through the first sources.
The first things I would recommend reading are the following excerpts from Kolman and Hill, Elementary Linear Algebra. The first one is on the correlation coefficient:
Kolman and Hill, Correlation Coefficient
Understanding this material on the correlation coefficient is not strictly necessary to understand principal components, but it will help you to understand how the basic data analysis is set up, and what the variance is measuring. It’s also interesting in its own right.
The second thing I would recommend reading is also an excerpt from Kolman and Hill, Elementary Linear Algebra:
Kolman and Hill, Dominant Eigenvalue and Principal Component Analysis
If you aren’t specifically interested in dominant eigenvalues in general (see the problem in the previous section), you could skip directly to the section on principal component analysis, and only refer back to the first part of the chapter as needed. I would recommend working through the explanations and examples, and perhaps trying an exercise.
If you want more detail, this tutorial by Lindsay Smith has a nicely paced, detailed explanation of all the elements that go into PCA, with examples:
Lindsay Smith, A Tutorial on Principal Components Analysis.
If you would like to go deeper into PCA, and learn more of the theory, this tutorial by Jonathon Shlens is good:
Jonathon Shlens, A Tutorial on Principal Component Analysis.
If you wanted to work through this tutorial as a project, it would touch on many of the topics that we have covered and also many of those I am planning for the rest of the term.
Markov Processes and Cryptoanalysis
The following article about using Markov processes to decipher messages is quite fun:
Persi Diaconis, The Markov Chain Monte Carlo Revolution
He also talks about other applications of Markov chains as models. The introduction should be readable for everyone, if you’re interested. Section 2 should be mostly possible to understand, based on what we have done, if you take it slowly. This could be an excellent project, to try to work through this section, and maybe to implement a similar model for a problem of this type. Sections 3, 4, and 5 are too advanced for this class, but it might be fun to browse ahead and see what sorts of math is being used (particularly if you took Abstract Algebra or Analysis…)
(Incidentally, Persi Diaconis was known for being both a mathematician and a magician. If you’re interested in magic, gambling, card tricks, etc, it might be interesting to look for some of his other works.)
Fibonacci sequence and discrete dynamical systems
You’ve probably seen the Fibonacci sequence before:
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, . . .
Each term in the sequence is the sum of the previous two terms, starting with $f_0=1$ and $f_1=1$:
$f_{n+1}=f_n + f_{n-1}$, for $n=1, 2, 3, \dotsc$.
You may know that there is a relation of the Fibonacci numbers to the “golden ratio” $\phi$:
$\lim_{n\to]infty}\dfrac{f_{n+1}}{f_n}=\phi$,
where $\phi\doteq 1.618033\ldots$. The golden ratio is the proportion of length to height of a “golden rectangle”. A “golden rectangle” is one for which, if you cut off a square, then the remaining rectangle is similar to the original:
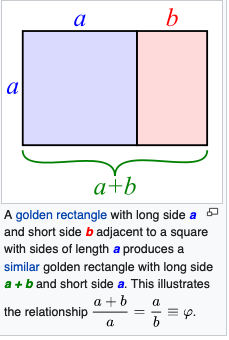
Perhaps more surprisingly, there is an exact formula for the nth Fibonacci number, in terms of the golden ratio:
$f_n=\dfrac{\phi^n-\psi^n}{\phi-\psi}$,
where $\psi=-\dfrac{1}{\phi}$. One of the surprising things about this formula is that there is no apparent reason, looking at it, that it should ever come out to a whole number! (Never mind that it comes out to a whole number for every value of n.)
There are at least two ways of deriving this formula. One is a calculus way, involving infinite series. The other involves linear transformations and eigenvalues. This set of problems is about deriving the closed-form formula above (and generalizing it, if you are interested in going that far).
Problem: Golden Ratio pre-amble
To solve the Fibonacci problem, it will help to figure out some things about the golden ratio first. You don’t have to, you can skip this and press ahead to the next question; but doing this one first will make the computations much cleaner.
a) Find a polynomial equation for the golden ratio $\phi$, based on the defining golden rectangle I mentioned above.
b) Find an exact expression for $\phi$. (Which root of the polynomial is it?)
c) Show that $\phi$ satisfies the equation $\phi^2=\phi + 1$. (If you do it right, this should be immediate, no calculation required!) This equation is quite useful for doing computations with $\phi$. For example, try writing $(2+\phi)^2$ in the form $a+b\phi$, with $a$ and $b$ integers.
d) Write $1/\phi$ in the form $a+b\phi$, for some rational $a$ and $b$.
e) (Theory, optional): The computations above are the main steps in showing that the set of all numbers $a+b\phi$, where $a$ and $b$ are rational, form a field. Complete this proof. (This is very similar to how we construct the field of complex numbers from the field of real numbers.)(This means that the computations below are actually over this field, called $\mathbb{Q}(\phi)$. Fields like this are very important in math.)
f) What is the other root of the defining polynomial for $\phi$? Write this other root in terms of $\phi$. (Hint: work out the factorization of the polynomial in terms of $\phi$.)
Now, here’s the translation of the Fibonacci numbers into a matrix form. I claim that the following equation holds, for any n=1, 2, 3, . . . :
$\begin{bmatrix}f_{n+1}\\f_n\end{bmatrix}=\begin{bmatrix}1 & 1\\1 & 0\end{bmatrix}\begin{bmatrix}f_{n}\\f_{n-1}\end{bmatrix}$.
Exercise:
a) Start with the vector $\begin{bmatrix}1\\1\end{bmatrix}$, corresponding to $n=1$, and multiply by the matrix above (let’s call it $T$) several times, to check numerically that it does in fact generate Fibonacci numbers.
b) (Optional) Prove that the matrix equation given above is valid for all positive integers $n$.
Now, finding Fibonacci numbers means finding large powers of the matrix $T=\begin{bmatrix}1 & 1\\1 & 0\end{bmatrix}$. But we have seen how to do this using eigenvalues and eigenvectors!
Problem: Exact formula for Fibonacci numbers from diagonalization
As we did for the Markov chain example recently, diagonalize the matrix $T$. That is, find the eigenvalues and corresponding eigenvectors of $T$. Write $T$ in the form $T=SDS^{-1}$, where $S$ is the change of basis matrix and $D$ is a diagonal matrix. Conclude that $T^n=SD^nS^{-1}$, and use this to explicitly calculate $T^n$. Finally, apply that to the starting vector $\begin{bmatrix}1\\1\end{bmatrix}$, and simplify, to find the exact formula for Fibonacci numbers.
Suggestions:
– CHECK your work at every stage. For example, if a vector $\vec{e}’_1$ is supposed to be an eigenvector of $T$, multiply it by $T$ and check that $T\vec{e}’_1=\lambda_1\vec{e}’_1$ as it should be. It’s easy to make algebra mistakes in this problem; try to catch them as quickly as possible.
– The computations are much neater if you do them all in terms of $\phi$ and $\psi$, and use the computation tricks I suggested above.
– Your final answer might simplify in a non-obvious way. If you get a final answer that looks different than the one I gave above, try substituting in $n=1,2,3$ into your formula and see if it works! If it does, then you know there is some tricky way to simplify it to the form I gave. It it doesn’t, then you know there is an algebra error somewhere…
Spectral graph theory
This topic is about how the shape of the graph is reflected in the eigenvalues of the graph Laplacian. The graph Laplacian is the operator $\Delta$ that we defined back in the Markov chain example. Since that operator defines diffusion in a graph, there is some intuition about how the eigenvalues connect to heat flow, and how the heat flow connects to the shape of the graph.
People are interested in this problem in both directions: given a graph, what we can say about the eigenvalues; and, computing the eigenvalues, what can we say about the graph. As a general rule, the theory is more in the first question, and the applications are more in the second question. A common type of applied question is, vaguely: we have a big complicated graph, how can we understand the shape and connectivity? And eigenvalues are one tool applied to this sort of question.
If you are interested in learning more, or taking this up as an extended problem/project, there are two ways you could proceed.
1) Experiment! This would be a computing question. Look up, or program yourself, an easy way of storing a graph, converting it to an adjacency matrix, and finding the graph Laplacian $\Delta$. Then, experiment: try different graphs, find their Laplacians, and use Python/SageMath (or whatever you prefer) to compute their eigenvalues. Try graphs that are long and spread out (like a line, or a circle), and compare them to graphs which are more “compact” (like complete graphs).
2) Look at references. There are two sets of slides for talks/tutorials I found that give a pretty understandable introduction. The first is a set of slides by D.J. Kelleher, which I found pretty detailed and readable:
D.J. Kelleher, Spectral Graph Theory.
The second is another set of slides. This one is a little less detailed, but it goes further, and could be a good reference point for learning more:
Daniel A. Spielman, Spectral Graph Theory and its Applications.
You could either read through these references from a more applied perspective—looking for computational problems that you could try out yourself—or from a more theoretical perspective, trying to understand some of the theorems stated.
If you wanted to go further in this topic, there is one best book, written by one of the pioneers and masters of this field:
Spectral Graph Theory, by Fan R.K. Chung, AMS 1997
The library has one copy of this book; if more than one person is interested, let me know, and I’ll try to rustle up another copy! Her book is perhaps a bit advanced for the level of this class, but if you take it slowly it should be comprehensible, and has all kinds of cool stuff in it.
Finite Element Modeling (Physics, Astronomy, Engineering…)
This question is about simulation of physical systems. It is something that is used throughout the physical sciences. Even if you aren’t interested in numerical simulation, it can be very instructive to learn how these models work; in particular, very often the “exact” differential equation models of physics are developed by starting with a discrete finite element model, and then taking the limit as the size of the elements goes to zero.
I will pick one physical problem to look at: wave motion. But the methods work very similarly for other physical problems: quantum wave functions, electric fields, heat flow, stresses, etc etc.
The classic wave motion problem is that of a stretched string with fixed ends (like a guitar string). We imagine that the length, tension, thickness, density, and composition of the string are all fixed at the beginning of the analysis. Depending on the initial motion I give to the string (by plucking or striking), a wide variety of different wave motions are possible:
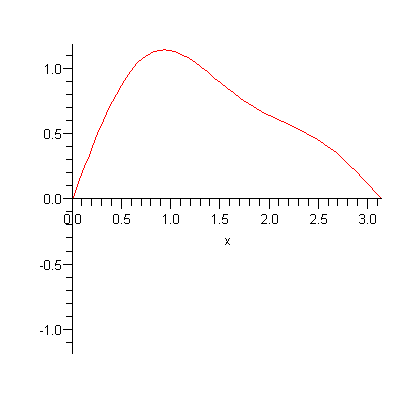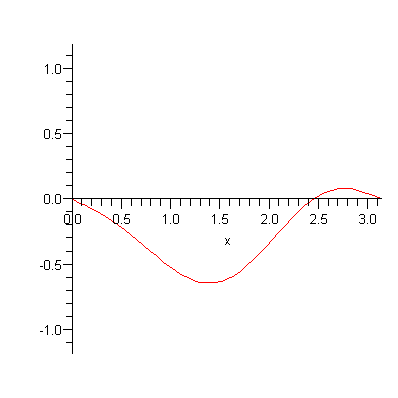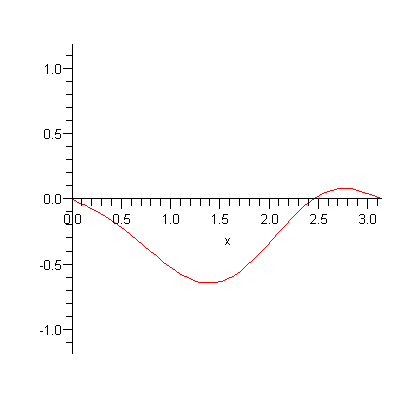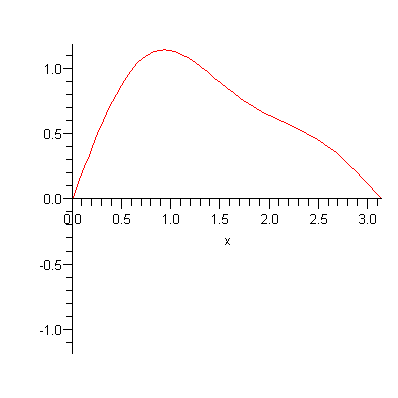
“Finite Element Modeling” means modeling this continuous string with a finite number of discrete pieces. I imagine that, instead of having a string of continuous constant density, I have a number of discrete masses, attached by ideal weightless strings that carry all the force of tension:
The idea is that we can simulate the continuous string by means of figuring out how these discrete masses are going to move. The approximation gets better as we take more, smaller masses, spaced more closely together. (Of course, if the physical system we are interested in really IS a bunch of discrete masses attached by strings, then we are already done: the finite element model will already be a good model!)

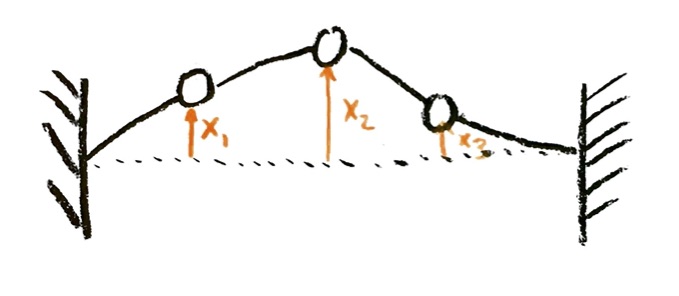
Let’s start with the three masses on a string that I have pictured above. Let’s look at motion in only one direction: assume that the masses can only move vertically in my diagram, not side to side, or in and out of the page. The ends are fixed in position, at the same height. Disregard gravity. The state of the system will then be determined if I know the displacements $x_1$, $x_2$, and $x_3$ of each of the three masses vertically from their rest positions, and also each of the three velocities $v_1$, $v_2$, and $v_3$ in the vertical direction. The value of $x_i$ will be negative if mass $i$ is below the rest position. The value of $v_i$ will be positive if mass $i$ is moving upwards, negative if mass $i$ is moving downwards.
We will collect all the displacements into a displacement vector, and all the velocities into a velocity vector:
$\vec{x}=\begin{bmatrix}x_1\\x_2\\x_3\end{bmatrix}$, $\vec{v}=\begin{bmatrix}v_1\\v_2\\v_3\end{bmatrix}$.
The vertical force on mass $i$ will have two parts, one from the string connecting to mass $i-1$, and one from the string connecting to mass $i+1$. (If the mass is at the end of the string, “mass $i-1$” or “mass $i+1$” may be replaced by the fixed end. So we might want to introduce the constants $x_0=0$ and $x_{n+1}=0$. In our example, $n=3$ and so we could think of $x_4=0$ for all time.)
To first approximation, the vertical component of the force on mass $i$ from the string to mass $i-1$ will be proportional to the difference in vertical heights of mass $i-1$ from mass $i$. (If you are a physics person, this is a good exercise to verify this claim!) Note that, if $x_{i-1}$ is less than $x_i$, then the force on mass $i$ from that string is downwards.
The constant of proportionality is dependent on lengths of the strings and string tension; let’s just call it a constant $k$.
Problem: Force matrix
a) In the example above, with three masses, write the vertical force $F_1$, $F_2$, $F_3$ on each mass. Each force will depend on the proportionality constant $k$, and also potentially on $x_1$, $x_2$, and $x_3$. (It also depends on $x_0$ and $x_4$, but since these are both the constant 0, you can drop them out in the end.)
b) Write those equations as $\vec{F}=kT\vec{x}$, where $T$ is a matrix.
c) Write out what the matrix $T$ would be if we had a string consisting of $n$ masses (rather than only 3 masses).
Now, the motions are determined by Newton’s law! The vertical acceleration $a_i$ of mass $i$ is given by
$a_i=\dfrac{1}{m_i}F_i$.
Since we have figured out the forces at any given position, we now know the accelerations:
Problem: Acceleration matrix
Show that $\vec{a}=\frac{k}{m}T\vec{x}$, where $T$ is the force matrix you found in the last question.
Now, there are two ways to go. We can leave time as continuous, in which case we get $n$ interlocked differential equations. We know, by definition, that
$\dfrac{\mathrm{d}^2 x_i}{\mathrm{d} t^2}=a_i$.
Since we have formulas for the $a_i$ in terms of the $x_j$, that gives us $n$ interdependent second-order differential equations for the $n$ quantities $x_i$. We can also collect these into one matrix differential equation.
Problem: Second-Order Differential Equations
a) In our example with three masses, write out the three second-order differential equations for $x_1$, $x_2$, and $x_3$.
b) Collect all three differential equations into one matrix differential equation (the left side will be $\dfrac{\mathrm{d}^2 \vec{x}}{\mathrm{d} t^2}$, the right side will be a matrix times $\vec{x}$).
c) How would this look for $n$ masses, rather than three?
It is also often convenient to break these $n$ second-order differential equations into $2n$ linked first-order differential equations. By definition,
$\dfrac{\mathrm{d} x_i}{\mathrm{d} t}=v_i$
and
$\dfrac{\mathrm{d} v_i}{\mathrm{d} t}=a_i$.
Since we have given formulas for the $a_i$, this gives $2n$ first-order differential equations for the $2n$ variables $x_i$ and $v_i$ (instead of $n$ second-order differential equations for the $n$ variables $x_i$).
The other way to approach this would be to also discretize time. We would break time into discrete steps of length $\Delta t$ (this is just a small time step, NOT related to the matrix $\Delta$ from an earlier question!!). In this case, the breaking into first-order differential equations is particularly helpful. We approximate the derivatives by finite differences,
$\dfrac{\mathrm{d} x_i}{\mathrm{d} t}\approx\dfrac{\Delta x_i}{\Delta t}$, $\dfrac{\mathrm{d} v_i}{\mathrm{d} t}\approx\dfrac{\Delta v_i}{\Delta t}$,
which gives us difference equations that approximate the differential equations. In each time step, each $x_i(t_{m+1})$ and $v_i(t_{m+1})$ is calculated by
$x_i(t_{m+1})=x_i(t_m)+\Delta x_i(t_m)$
$v_i(t_{m+1})=v_i(t_m)+\Delta v_i(t_m)$,
where the changes are computed by
$\Delta x_i(t_m)=v_i(t_m)\Delta t$
$\Delta v_i(t_m)=a_i(t_m)\Delta t$.
Here, $v_i(t_m)$ is just the running value of $v_i$ at that time step; but $a_i(t_m)$ stands for the formula for the acceleration of mass $i$, in terms of the various $x_j$, that you computed before.
Problem: Computing with discrete time
(Optional) If you would like to do a computing problem, it is interesting to carry out the computations with discrete time that I have described. Try setting up the discrete time equations, using three masses, and choosing some reasonable value for the constant $k/m$ (you might want to try something like $k/m=0.1$, so it doesn’t jump around too quickly). Then pick some starting value for the $x_i$. See if your simulation gives you something at least half-way realistic for wave motion. (If it’s way off, there is likely an algebra or sign error in there somewhere…)
Now, let’s go back to the differential equation version (continuous time), and see what we can figure out. It turns out that the eigenvectors and eigenvalues of $T$ are crucial here.
Problem: Decoupling equations; role of eigenvalues
a) Suppose that there exists some eigenvector $\vec{e}_1$ of the matrix $T$. Suppose we start the system, at the initial time, with position being a scalar multiple of that eigenvector, $\vec{x}=A_0\vec{e}_1$ for some scalar $A_0$, and with zero velocity. See if you can explain why the system will always have a position $\vec{x}$ that is a scalar multiple $A\vec{e}_1$ (the multiple $A$ changing over time). (It will be easier to give a precise proof after you complete the next parts.)
b) Suppose we have a differential equation
$\dfrac{\mathrm{d}^2 x}{\mathrm{d} t^2}=-Cx$,
for some scalar function of time $x=x(t)$ and some positive constant $C$. Suppose that the initial condition is $x(0)=A_0$, and $v(0)=0$ (zero initial velocity). Show that $x(t)=A_0\cos(\omega t)$ is a solution to the differential equation, with $\omega=\sqrt{C}$. (Just substitute in and check that the equation is satisfied.)
c) Suppose we have a differential equation
$\dfrac{\mathrm{d}^2 A\vec{e}}{\mathrm{d} t^2}=-CA\vec{e}$,
where $A=A(t)$ is a scalar function of time $t$, and $\vec{e}$ is some fixed vector in $\mathbb{R}^n$. Using the previous part, write out the solution of this differential equation. (Write out the vector components to see what this is saying.)
d) Going back to the first part, can you say what the solution of the differential equation is going to be, when the initial positions $\vec{x}_0(0)$ are an eigenvector of $T$? What does this say about the physical motion in this case?
Problem: Eigenvalues and eigenvectors when n=3
a) In our example above, with three masses, find all the eigenvalues and eigenvectors of the matrix $T$.
b) Draw out what the three eigenvectors look like, as positions of the masses on the string. Describe what the motion of each eigenvector (or “mode”) would look like (if we start in one mode, then all positions at later times are scalar multiples of that mode).
c) Describe what the frequencies of each mode are. In particular, say what the frequencies of the second and third mode are, in comparison to the first mode.
d) Diagonalize the matrix $T$. Use this to give a general solution of the differential equation of motion, for any initial condition $\vec{x}(0)$ (and initial velocity $\vec{v}(0)=0$).
This doesn’t work only for stretched strings. For example, we could have a membrane with a fixed edge, like a drum head:
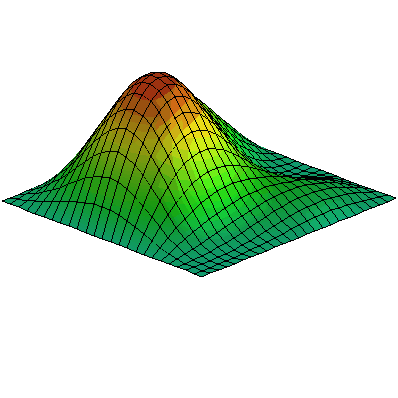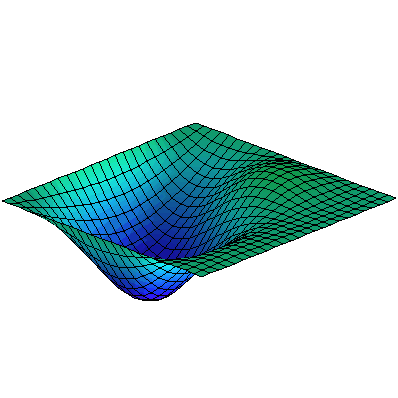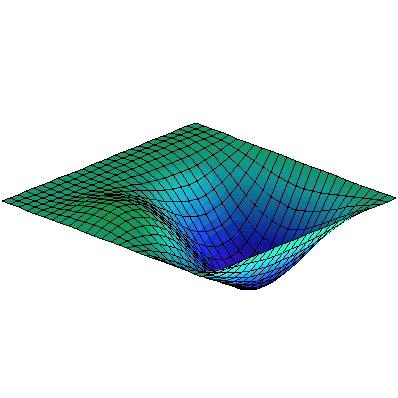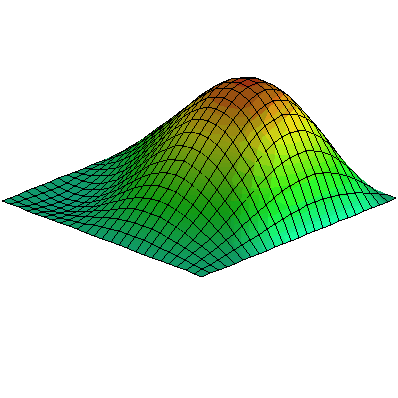
We can set up the finite element model in a similar way.
Problem: Vibrating Membrane
Suppose that we have a square membrane, fixed at the edges, like the picture above. Let’s model this with nine discrete masses, in a $3\times 3$ square grid, connected by a square grid of weightless stretched strings. There are strings attached to a fixed square frame, around the $3\times 3$ grid of discrete masses. The rules will be the same: we only consider vertical displacements $x_i$ and velocities $v_i$, and we assume that the vertical forces are simply proportional to differences in height from neighbors, as before.
Use this setup to write the matrix differential equation as before. Everything should be the same as with the string, except for the $9\times 9$ matrix $T$, which will be different. (Actually, I started kind of large, didn’t I? You might want to try doing a $2\times 2$ grid of masses first, which would give you a $4\times 4$ matrix $T$.)
(I’m not asking you to do any of the later steps here, which would be harder! I’m just asking for the initial setup, which corresponds to finding the matrix $T$.)
There’s plenty more I could ask here, but this is already too much!